WebLicht - Créer sa chaîne
Weblicht
Service proposé par CLARIN Lien vers l'outil : https://weblicht.sfs.uni-tuebingen.de/weblicht/ Lien vers la documentation : User Manual Lien vers la documentation sur le format TCF : The TCF Format
Créer une chaîne de traitement sur WebLicht
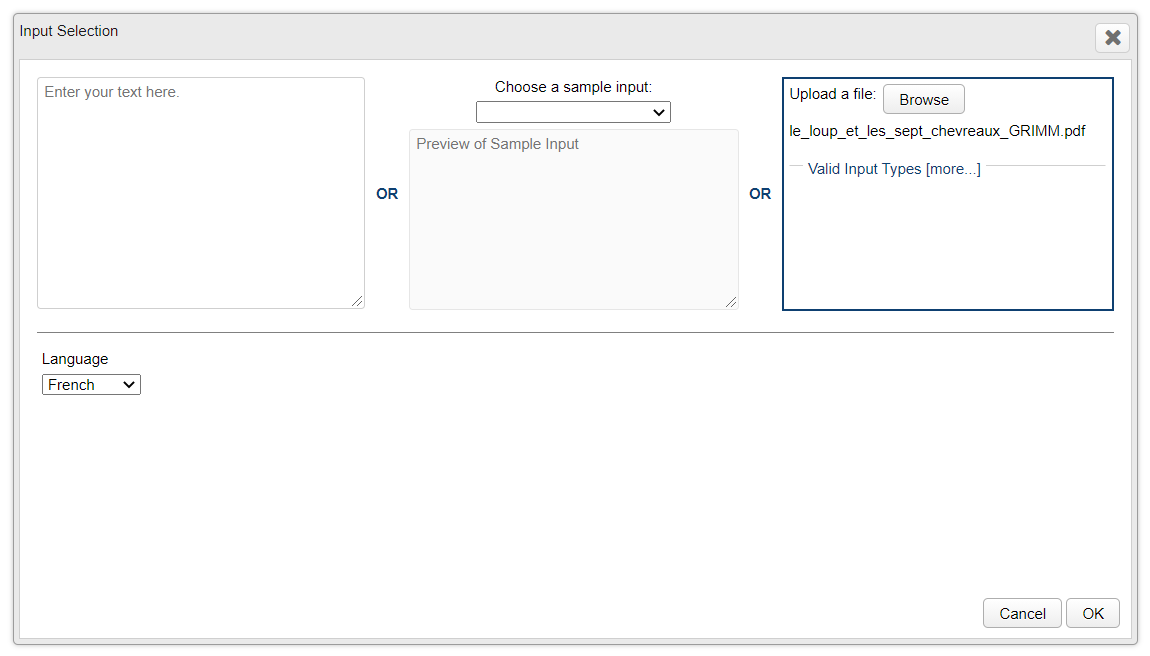
Interface Web
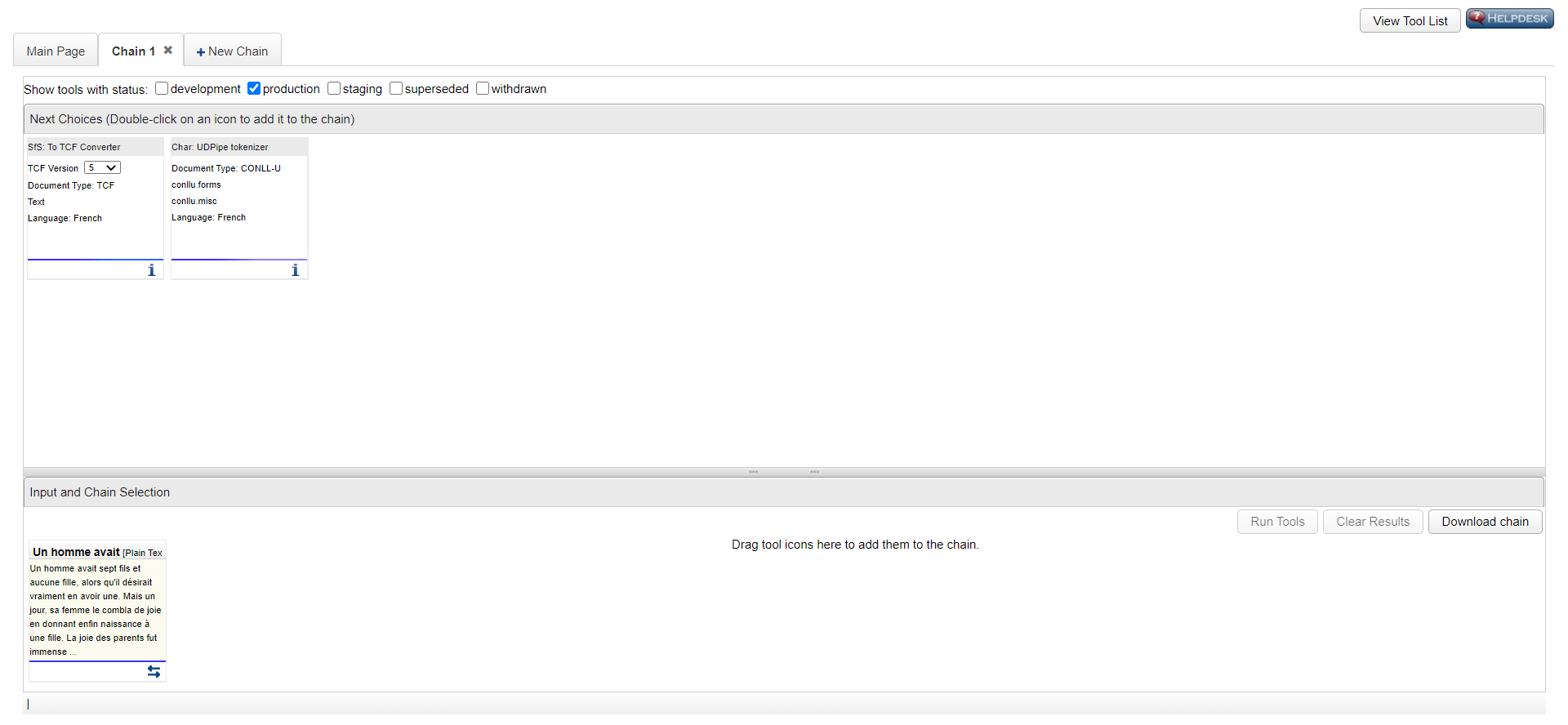 L'écran est découpé en deux cases :
La case du haut "Next Choices" (= choix suivants) propose des outils à ajouter à la chaîne de traitement que vous êtes en train de créer.
La case du bas "Input and Chain Selection" (= fichier d'entrée et chaîne sélectionnée) présente votre chaîne de traitement avec comme premier élément le texte d'entrée.
L'écran est découpé en deux cases :
La case du haut "Next Choices" (= choix suivants) propose des outils à ajouter à la chaîne de traitement que vous êtes en train de créer.
La case du bas "Input and Chain Selection" (= fichier d'entrée et chaîne sélectionnée) présente votre chaîne de traitement avec comme premier élément le texte d'entrée.
Ajouter un élément à la chaîne
Dans la case du haut où apparaissent les différents outils disponibles, vous pouvez : Faire un double-clique sur l'outil pour que WebLicht l'ajoute à la suite de votre chaîne Faire un glisser-déposer d'un outil vers la case du bas "Input and Chain Selection" pour l'ajouter à votre chaîne. Lorsque vous ajoutez un outil à la chaîne, d'autres outils seront proposés. WebLicht propose des outils pour que l'entrée de l'outil suivant soit pertinente avec la sortie de l'outil précédent.
Si vous souhaitez plus d'informations sur l'un des outils proposés sur WebLicht, cliquez sur l'icône  située en dessous à droite de chaque outil. Vous obtiendrez alors une description de l'outil, des informations sur les créateurs de l'outil, le contact, le PID et sur les données d'entrée et de sortie.
située en dessous à droite de chaque outil. Vous obtiendrez alors une description de l'outil, des informations sur les créateurs de l'outil, le contact, le PID et sur les données d'entrée et de sortie.
Si vous souhaitez changer de texte d'entrée, vous pouvez cliquer sur l'icône  située en dessous de la case dédiée à votre texte d'entrée.
située en dessous de la case dédiée à votre texte d'entrée.
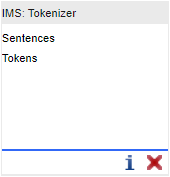
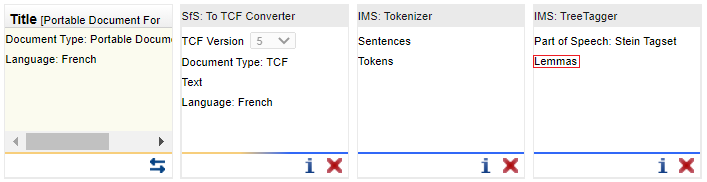
Les outils sont représentés dans des cases. Dans la partie grisée du haut figure le nom de l'outil. Dans l'exemple suivant, il s'agit de "IMS : Tokenizer". Au milieu, dans la case centrale blanche, sont données les sorties de l'outil : éléments que l'outil va permettre d'ajouter à la chaîne. Dans l'exemple suivant d'un simple tokeniseur, l'outil va rajouter un découpage du texte en phrases et en tokens. Il va donc rajouter des éléments de types "Sentences" (= phrases) et "Tokens". L'icône mentionnée précédemment permet donc de donner des informations plus détaillées sur l'outil et la croix rouge située en bas à droite à côté de l'icône sert à retirer un outil ajouté à la chaîne de traitement et retirera également tous les outils suivants.
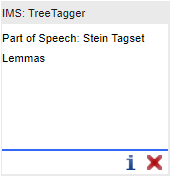
L'outil suivant s'appelle "IMS : TreeTagger" Sa sortie va rajouter à la chaîne des éléments "Part of Speech" (= étiquettes morpho-syntaxiques ou parties du discours) et "Lemmas" (= lemmes) qui correspondent aux annotations en parties du discours et aux lemmes.
Lorsque la chaîne que vous avez créée vous satisfait, cliquez sur le bouton  (lancer l'exécution de la chaîne) situé à droite dans la case de la chaîne de traitement.
(lancer l'exécution de la chaîne) situé à droite dans la case de la chaîne de traitement.
Aperçu des étapes de la chaîne de traitement pour le français
Selon votre texte d'entrée (langue et format), WebLicht vous proposera un certain nombre d'outils adaptés. Les étapes suivantes sont données à titre d'exemple.
Etape 1
Entrée : application/msword (DOC) | application/pdf (PDF) | application/rtf (RTF) | application/vnd.openxmlformats-officedocument.wordprocessingml.document (DOC) Outil proposé : SfS : To TCF Converter
Entrée : text/plain (TXT) Outils proposés : SfS : To TCF Converter Char : UDPipe tokenizer
Entrée : DTA/TEI Outil proposé : BBAW : TEI-to-TCF encoder
Etape 2
Entrée : text/tcf+xml Outils proposés : SfS : BlingFire Tokenizer IMS : Tokenizer
Entrée : appplication/conllu tokenisé Outil proposé : Char : UDPipe tagger
Etape 3
Entrée : text/tcf+xml tokenisé Outils proposés : CLAR : TextCorpus2Lexicon IMS : TreeTagger
Entrée : application/conllu sortie de UDPipe tagger Outil proposé : Char : UDPipe parser
Etape 4
Entrée : text/lexicon+xml Outils proposés : CLAR : Cooccurrences (sentence) for fra_news_2011_3M CLAR : Cooccurrences (right neighbour) for fra_news_2011_3M CLAR : Cooccurrences (left neighbour) for fra_news_2011_3M CLAR : Frequency webservice for fra_news_2011_3M CLAR : Sentences/TextCorpus webservice for fra_news_2011_3M
Entrée : application/conllu sortie de UDPipe parser Outil proposé : SfS : conll2tcf-converter
Entrée : text/tcf+xml tokenisé et lemmatisé Outil proposé : SfS : Lemma Frequencies
Visualisation des résultats
Visualisation
Description
Cette vue permet d'afficher vos résultats sous forme schématique.
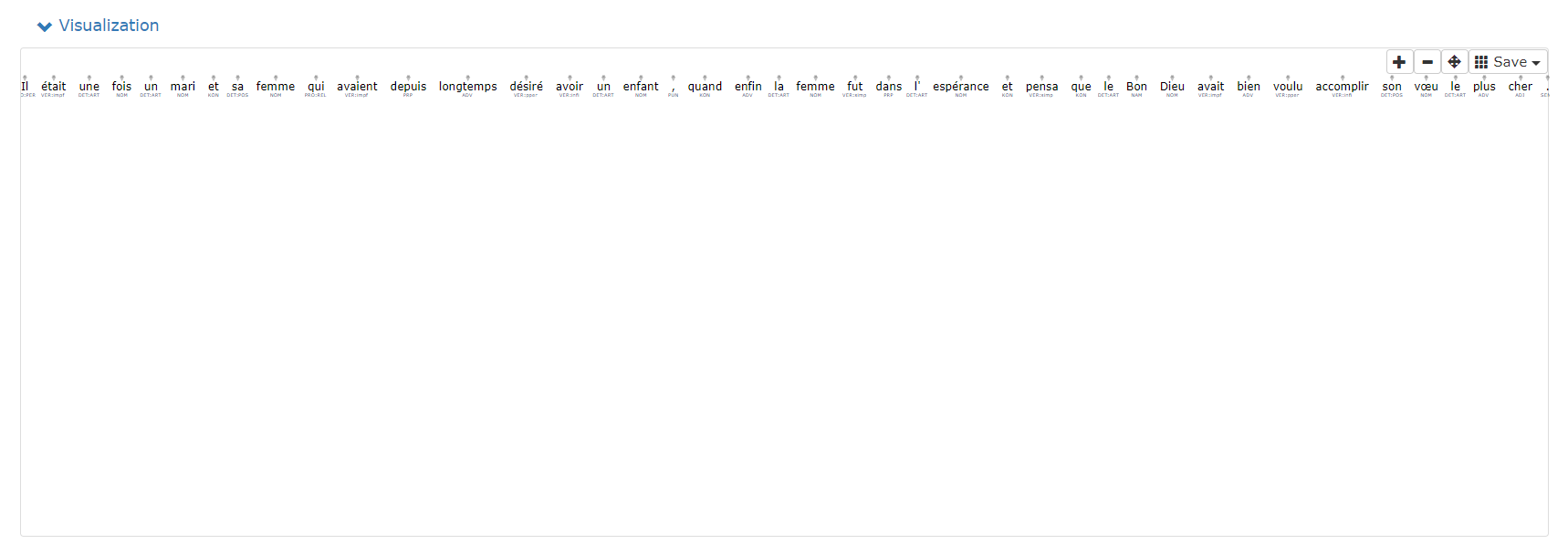 Cette vue est particulièrement utile pour certaines annotations telles que l'annotation des dépendances, car la forme schématique de type arbre syntaxique permet de mieux visualiser et de comprendre plus facilement ce type d'annotation.
Cette vue est particulièrement utile pour certaines annotations telles que l'annotation des dépendances, car la forme schématique de type arbre syntaxique permet de mieux visualiser et de comprendre plus facilement ce type d'annotation.
Dans le cas de la lemmatisation et annotation en parties du discours, cette vue représente chaque token de la phrase avec, en dessous du token, son étiquette POS. Survoler le token, permet d'afficher son lemme et son ID (position du mot dans la phrase).
Sauvegarder les résultats de la vue
Il est possible de sauvegarder les résultats de cette vue au format de votre choix (SVG, PDF, PNG, JPEG) proposé dans la liste déroulante située en haut à droite de cette vue :
Tableau
Description
Cette vue permet d'afficher les résultats sous la forme d'un tableau :
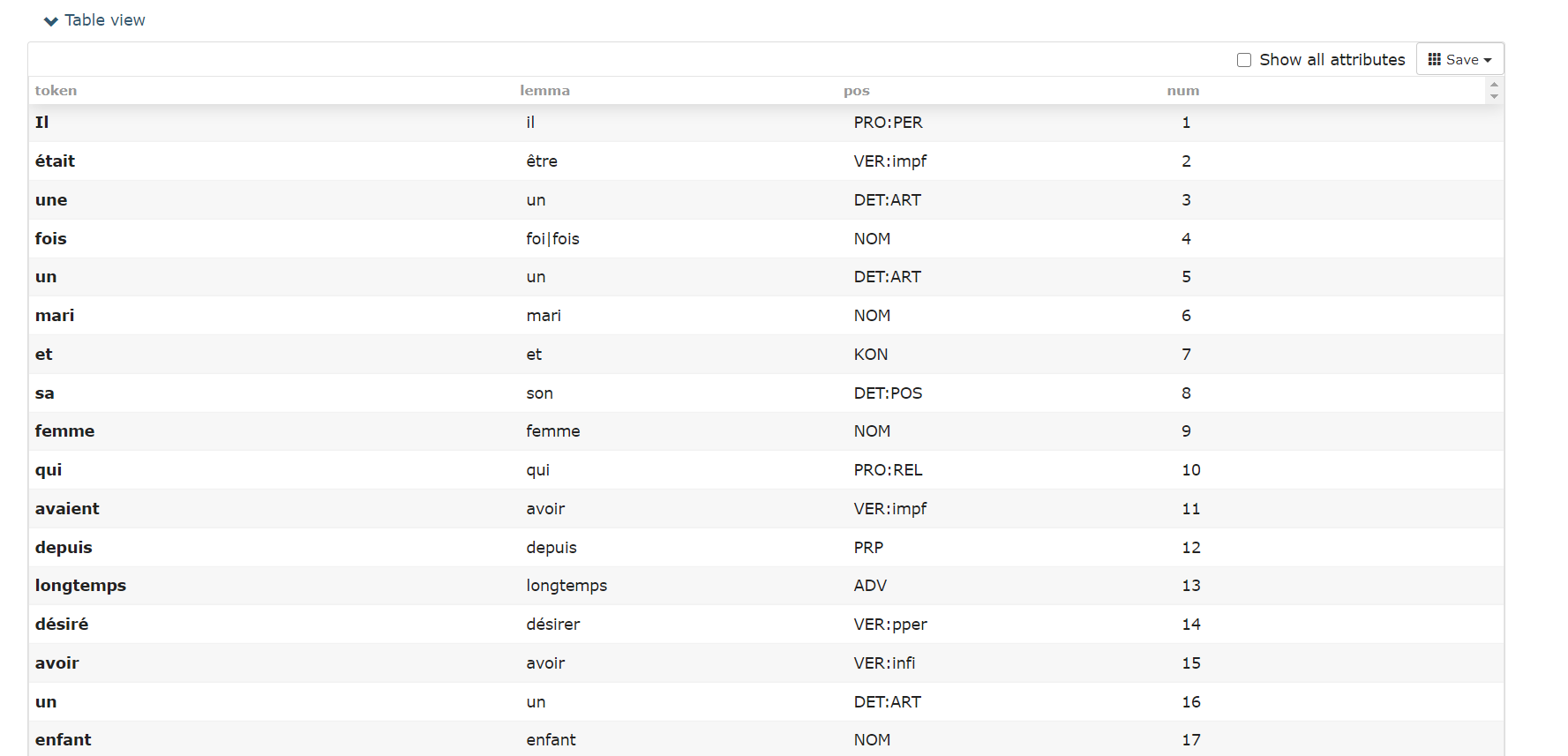 La première colonne représente le token, chaque ligne correspond à un token différent.
La deuxième colonne représente son lemme.
La troisième colonne représente son étiquette de partie du discours.
La dernière colonne représente son identifiant dans la phrase.
La première colonne représente le token, chaque ligne correspond à un token différent.
La deuxième colonne représente son lemme.
La troisième colonne représente son étiquette de partie du discours.
La dernière colonne représente son identifiant dans la phrase.
Sauvegarder les résultats de la vue
Il est possible de sauvegarder les résultats de cette vue au format CSV en appuyant sur "Save" (= sauvegarder) en haut à droite de cette vue et en choisissant de sauvegarder la première phrase ou les 1 000 premières phrases du texte :

Phrases en contexte
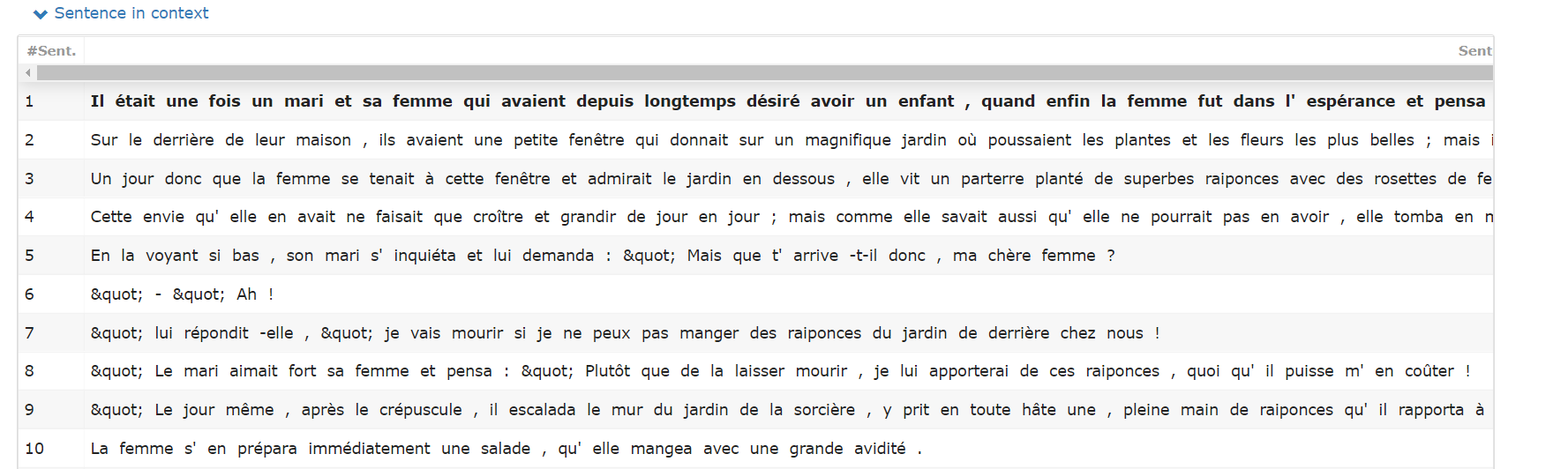
Description
Cette vue représente le découpage du texte par phrases. Chaque phrase du texte est accompagnée de son identifiant :
Télécharger les résultats
Une fois l'analyse effectuée, vous verrez apparaître deux nouvelles icônes en dessous de chaque outil de la chaîne de traitement qui viendront s'ajouter à l'icône :
 : Permet de visualiser à l'écran les annotations effectuées à chaque étape de la chaîne de traitement. Dans le cas de chaîne par défaut (chaîne pré-créée provenant de "Easy Mode"), vous n'avez pas besoin d'appuyer sur cette icône pour visualiser les résultats sauf si vous souhaitez les visualiser étape par étape (ou outil par outil).
: Permet de visualiser à l'écran les annotations effectuées à chaque étape de la chaîne de traitement. Dans le cas de chaîne par défaut (chaîne pré-créée provenant de "Easy Mode"), vous n'avez pas besoin d'appuyer sur cette icône pour visualiser les résultats sauf si vous souhaitez les visualiser étape par étape (ou outil par outil).
 : Permet de sauvegarder les résultats de l'annotation à chaque étape de la chaîne de traitement au format TCF+XML. Le format CONLLU est également un format disponible sur WebLicht.
Pour plus d'informations sur le format TCF, vous pouvez consulter la documentation de WebLicht sur ce format.
Pour plus d'informations sur le format CoNLL-U, vous pouvez consulter la documentation d'Universal Dependencies sur ce format.
: Permet de sauvegarder les résultats de l'annotation à chaque étape de la chaîne de traitement au format TCF+XML. Le format CONLLU est également un format disponible sur WebLicht.
Pour plus d'informations sur le format TCF, vous pouvez consulter la documentation de WebLicht sur ce format.
Pour plus d'informations sur le format CoNLL-U, vous pouvez consulter la documentation d'Universal Dependencies sur ce format.
Exemples de chaînes de traitement
_Des exemples de chaînes de traitement sont donnés à titre indicatif. Il est parfois possible d'utiliser d'autres outils pour parvenir au résultat souhaité. _
Comment réaliser une lemmatisation ?
Création d'une chaîne de traitement qui permet une lemmatisation
Entrée : Un texte français au format PDF
Sortie voulue : Lemmes
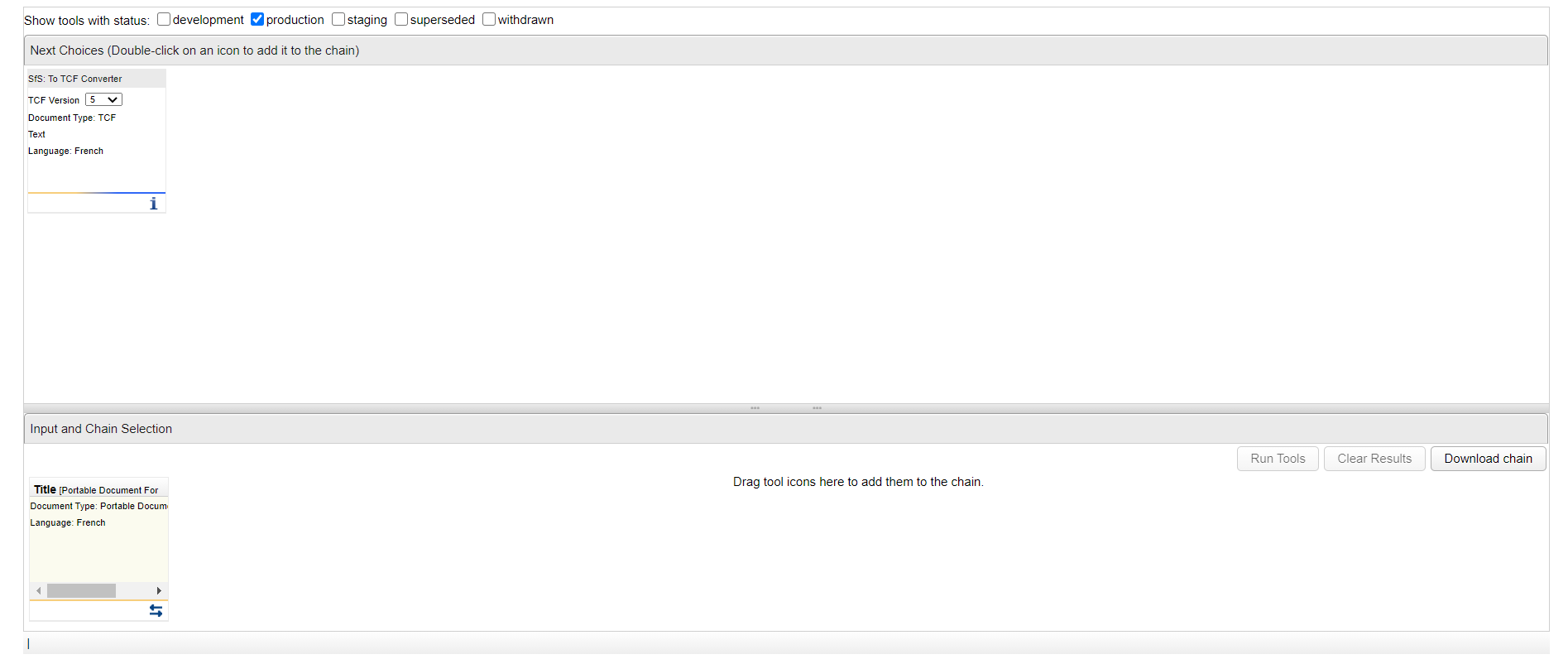
Je dois transformer mon texte d'entrée vers le format TCF utilisé dans WebLicht. De plus, il s'agit du seul outil qui m'est proposé :
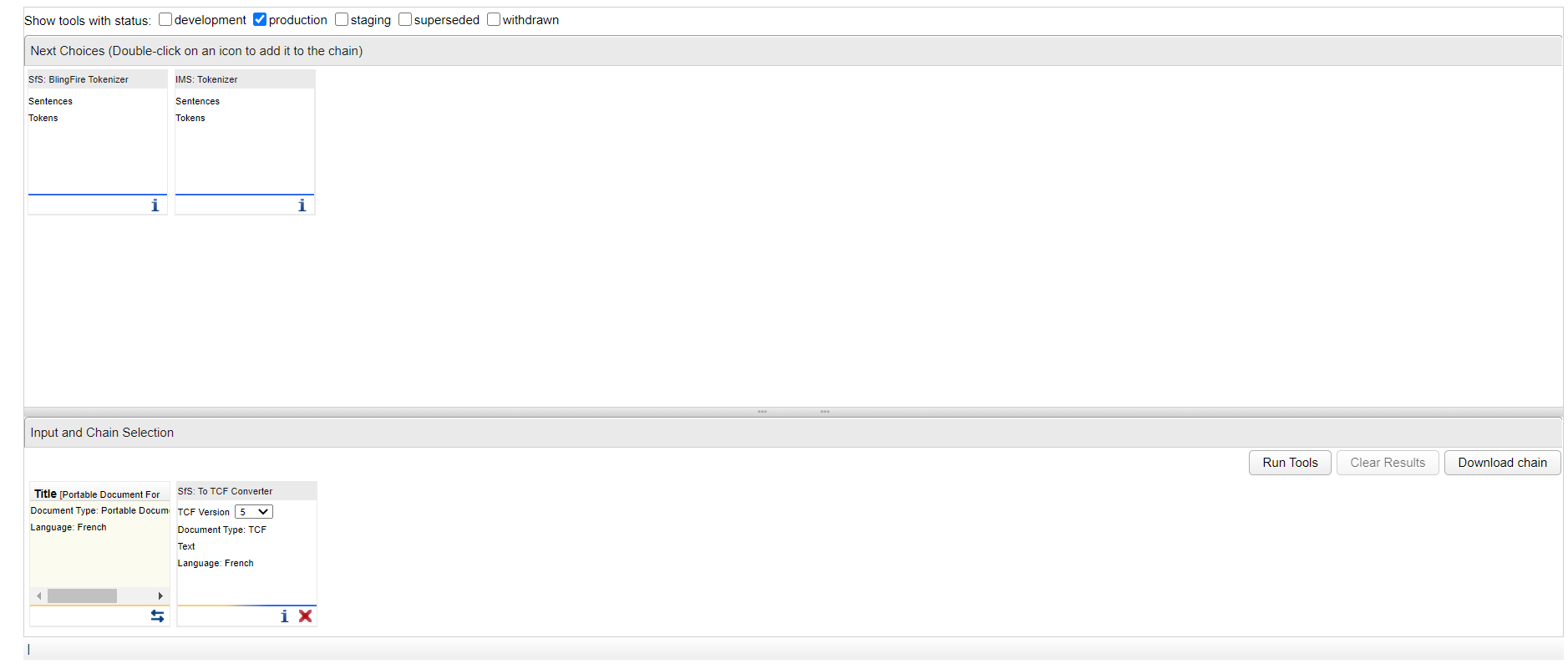
Je dois ensuite découper mon texte en tokens, j'utilise donc au choix l'un des deux tokeniseurs proposés :
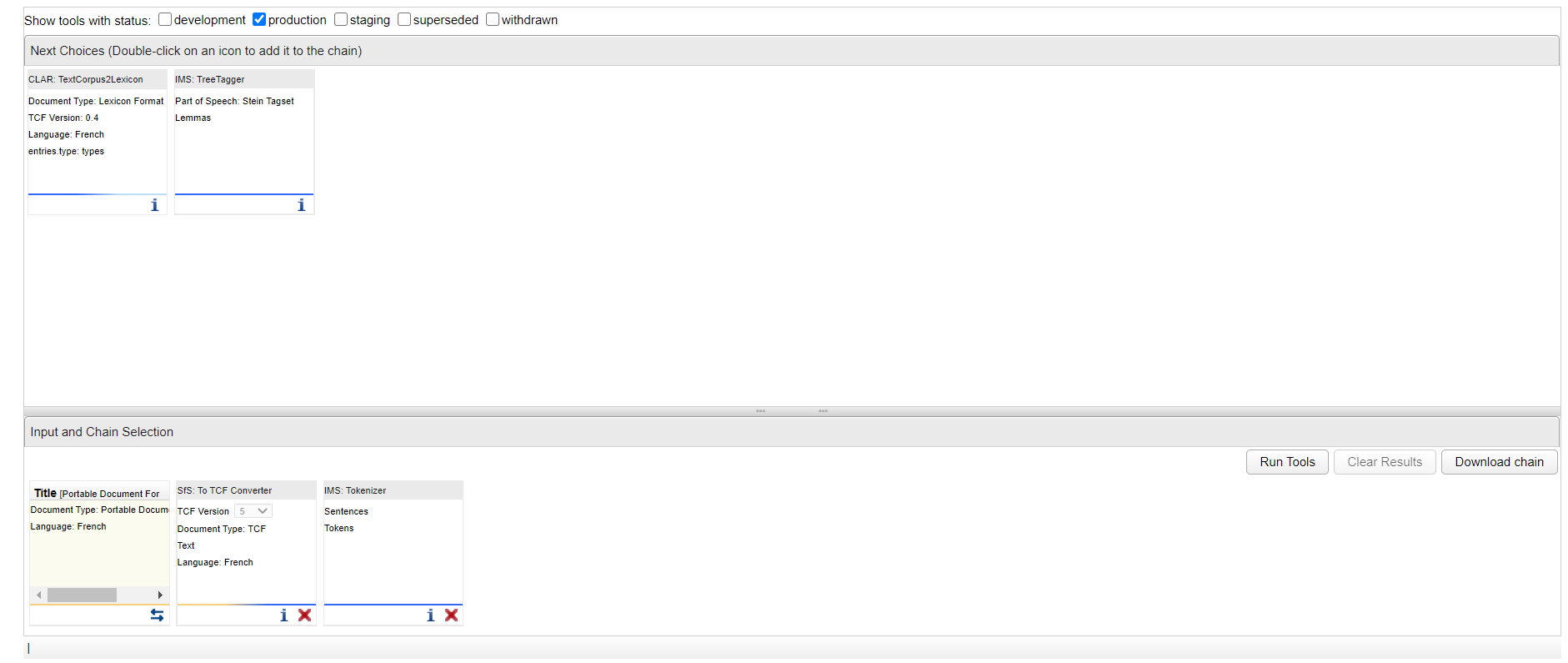
Je vois que l'outil "IMS : TreeTagger" devrait bien effectuer une lemmatisation (ainsi qu'une annotation en parties du discours) :
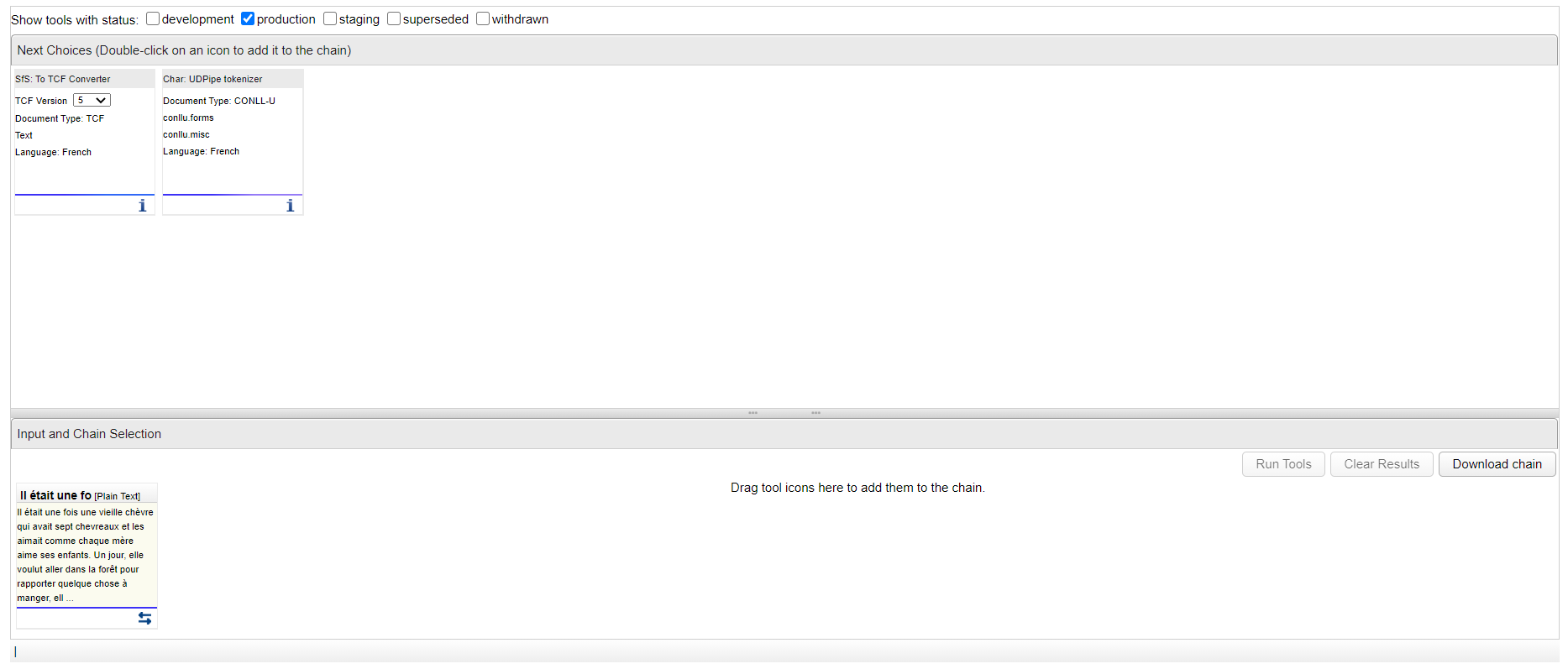
Ma chaîne de traitement finale pour effectuer une lemmatisation est donc la suivante :
Je peux donc lancer l'annotation en cliquant sur le bouton .
Sortie
Une fois l'analyse effectuée, je peux :
Télécharger mes résultats en cliquant sur l'icône apparue en-dessous de l'outil "IMS : TreeTagger" qui a effectué la lemmatisation de mon texte.
Visualiser mes résultats en cliquant sur l'icône apparue en-dessous de l'outil "IMS : TreeTagger" qui a effectué la lemmatisation de mon texte.
Téléchargement des résultats au format TCF
Les annotations sont téléchargées au format utilisé dans WebLicht, le format TCF (XML). Les lemmes y sont ajoutés de la manière suivante :
<tc:lemmas xmlns:tc="<http://www.dspin.de/data/textcorpus">
<tc:lemma ID="l_0" tokenIDs="t1">il</tc:lemma>
<tc:lemma ID="l_1" tokenIDs="t2">être</tc:lemma>
<tc:lemma ID="l_2" tokenIDs="t3">un</tc:lemma>
<tc:lemma ID="l_3" tokenIDs="t4">foi|fois</tc:lemma>
<tc:lemma ID="l_4" tokenIDs="t5">un</tc:lemma>
<tc:lemma ID="l_5" tokenIDs="t6">vieux</tc:lemma>
<tc:lemma ID="l_6" tokenIDs="t7">chèvre</tc:lemma>
<tc:lemma ID="l_7" tokenIDs="t8">qui</tc:lemma>
<tc:lemma ID="l_8" tokenIDs="t9">avoir</tc:lemma>
<tc:lemma ID="l_9" tokenIDs="t10">sept</tc:lemma>
<tc:lemma ID="l_10" tokenIDs="t11">chevreau</tc:lemma>
[...]
<tc:lemma ID="l_1224" tokenIDs="t1225">vieux</tc:lemma>
<tc:lemma ID="l_1225" tokenIDs="t1226">chèvre</tc:lemma>
<tc:lemma ID="l_1226" tokenIDs="t1227">danser</tc:lemma>
<tc:lemma ID="l_1227" tokenIDs="t1228">avec</tc:lemma>
<tc:lemma ID="l_1228" tokenIDs="t1229">eux</tc:lemma>
<tc:lemma ID="l_1229" tokenIDs="t1230">.</tc:lemma>
</tc:lemmas>
ID="l_0" : représente l'ID du lemme. Dans cet exemple, le lemme ayant l'identifiant "l_5" est "vieux". tokenIDs="t1" : représente l'ID permettant d'identifier le token de départ. Dans cet exemple, le token ayant l'identifiant "t6" est "vieille" :
<tc:tokens xmlns:tc="http://www.dspin.de/data/textcorpus">
<tc:token ID="t1">Il</tc:token>
<tc:token ID="t2">était</tc:token>
<tc:token ID="t3">une</tc:token>
<tc:token ID="t4">fois</tc:token>
<tc:token ID="t5">une</tc:token>
<tc:token ID="t6">vieille</tc:token>
<tc:token ID="t7">chèvre</tc:token>
[...]
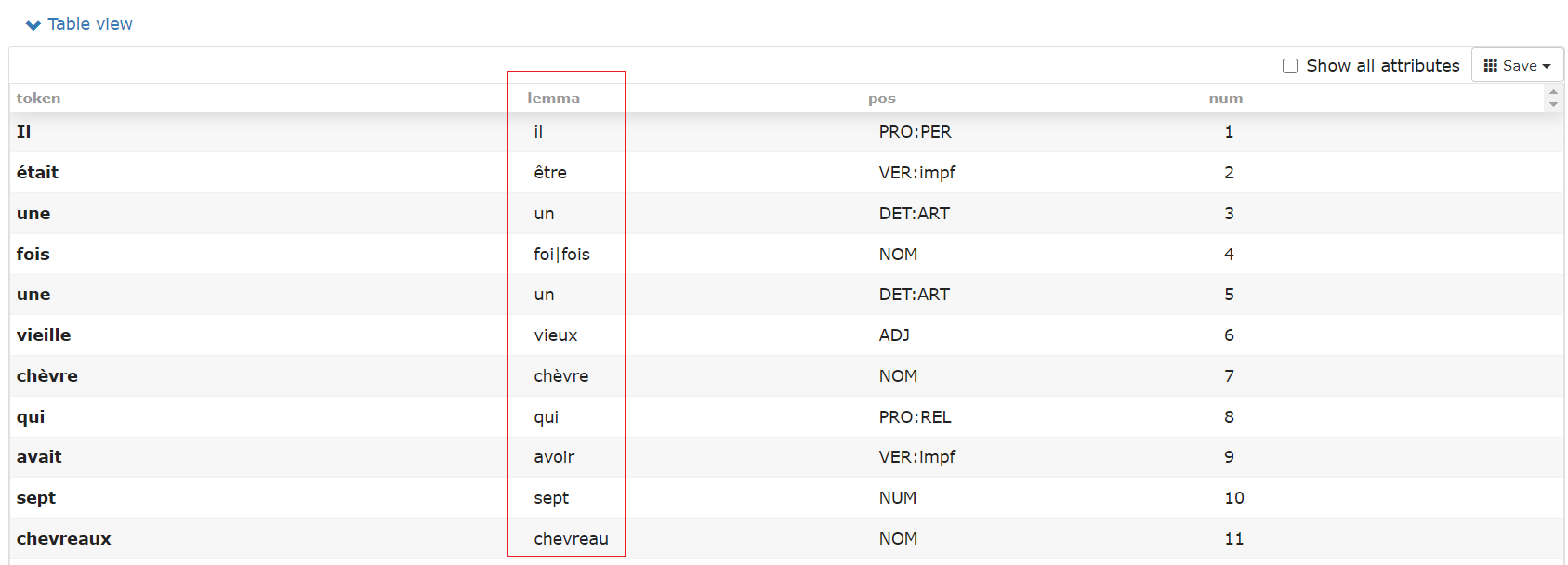
Visualisation des résultats (exemple "Table View")
La lemmatisation a bien été effectuée et les résultats sont bien visibles dans la visualisation. La colonne 2 du tableau "Table View" affiche bien les lemmes de chaque token de la colonne 1.
Comment réaliser une annotation en dépendances ?
Pour le français, un seul outil permet à l'heure actuelle d'effectuer une annotation des relations de dépendances. Il s'agit de l'outil UDPipe "Char : UDPipe parser". Comme mentionné précédemment, pour utiliser les outils de UDPipe et le format CONLLU, le texte d'entrée doit être de type text/plain.
Création de la chaîne de traitement permettant une annotation des dépendances
Entrée : Un texte brut en français
Sortie voulue : Les relations de dépendances entre les mots
La première étape consiste donc à transformer mon format text/plain en format conllu tokenisé. J'utilise l'outil "Char : UDPipe tokenizer" :
Il faut ensuite ajouter les lemmes et annotations des parties du discours, nécessaires pour pouvoir utiliser dans l'étape suivante l'outil qui permet de rajouter les relations de dépendances. Je peux donc glisser-déposer l'outil "Char : UDPipe tagger" :
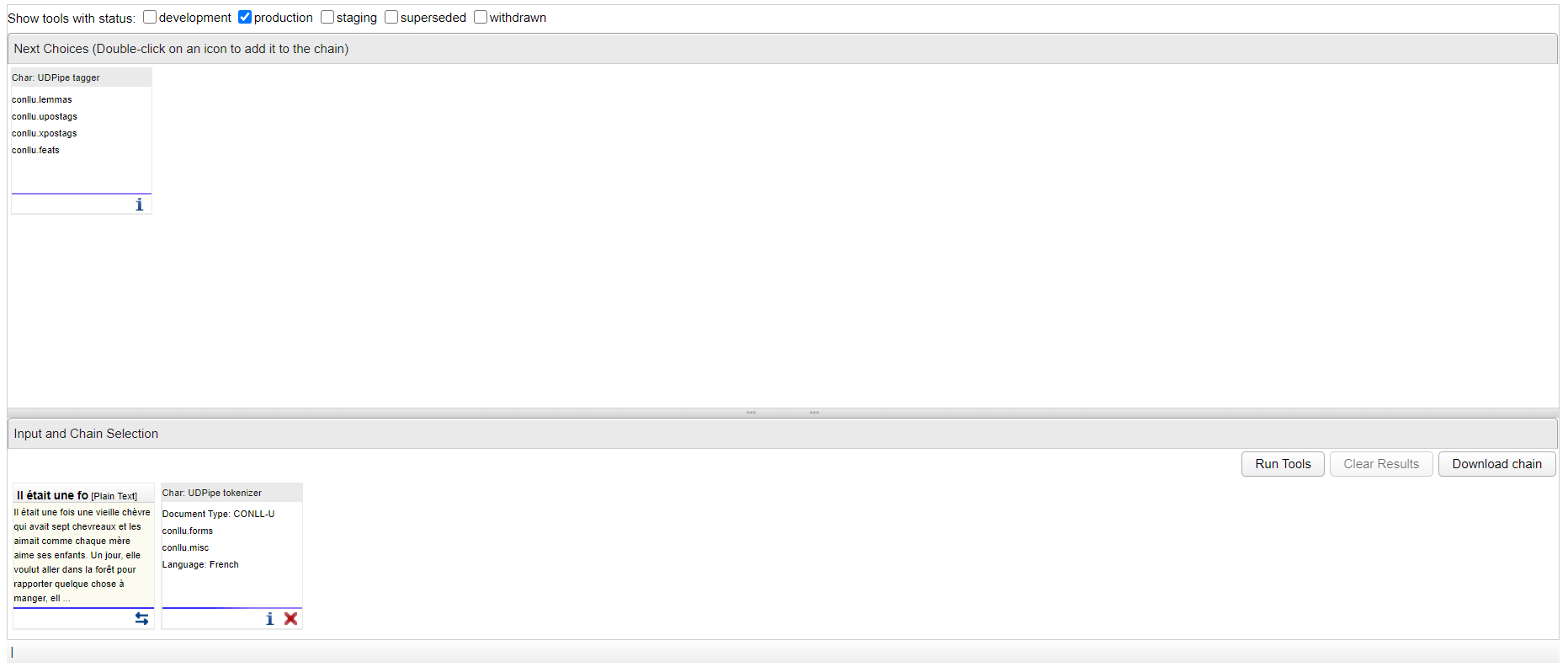
Je peux enfin glisser-déposer l'outil qui permettra l'ajout des étiquettes des dépendances "Char : UDPipe parser" :
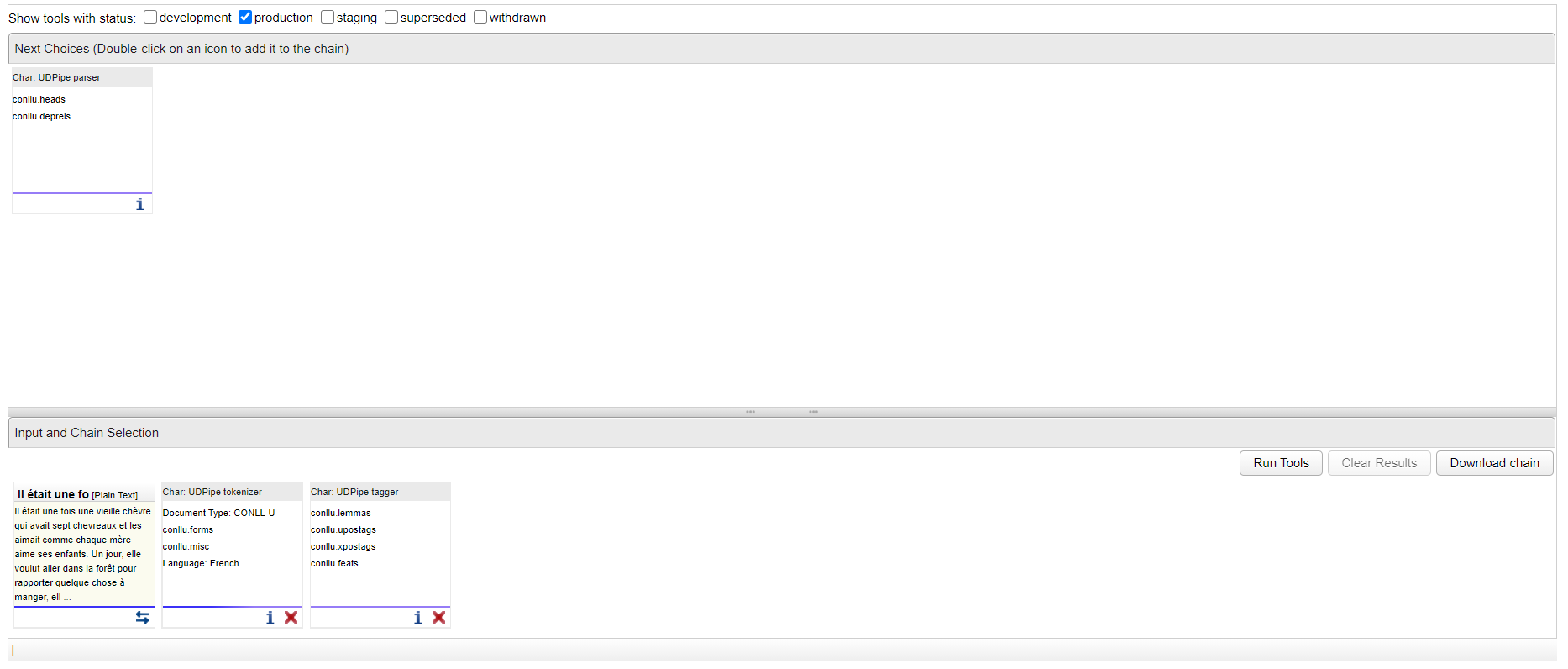
Ma chaîne de traitement finale pour effectuer une annotations des relations de dépendances est donc la suivante :
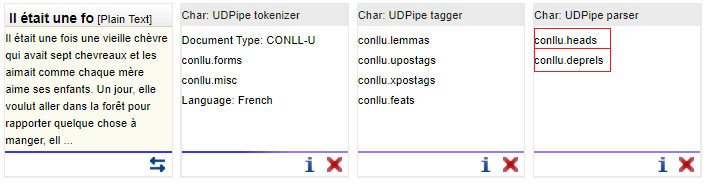
Bonus : Si le format CONLLU n'est pas souhaité, il est possible de convertir la sortie fournie par les outils de UDPipe vers la sortie TCF en utilisant l'outil "SfS : conll2tcf-converter" :
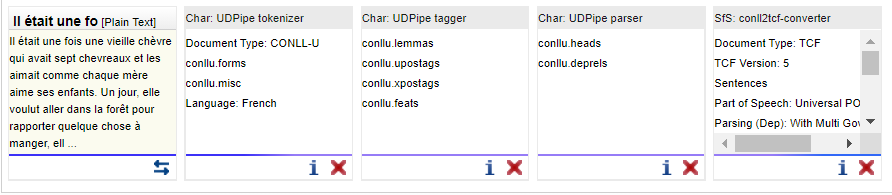
Je peux donc lancer l'annotation en cliquant sur le bouton .
Sortie
Une fois l'analyse effectuée, je peux donc :
Télécharger mes résultats en cliquant sur l'icône apparue en-dessous du dernier outil de la chaîne (pour avoir toutes les annotations).
Visualiser mes résultats en cliquant sur l'icône apparue en-dessous du dernier outil de la chaîne (pour avoir toutes les annotations).
Téléchargement des résultats au format CONLLU
Dans le cas où le format CONLLU a été gardé et où la conversion vers TCF n'a pas été effectuée
# newdoc
# newpar
# sent_id = 1
# text = Il était une fois une vieille chèvre qui avait sept chevreaux et les aimait comme chaque mère aime ses enfants.
1 Il il PRON _ Gender=Masc|Number=Sing|Person=3|PronType=Prs 7 nsubj _ _
2 était être AUX _ Mood=Ind|Number=Sing|Person=3|Tense=Imp|VerbForm=Fin 7 cop _ _
3 une un DET _ Definite=Ind|Gender=Fem|Number=Sing|PronType=Art 4 det _ _
4 fois fois NOUN _ Gender=Fem|Number=Sing 7 obl:mod _ _
5 une un DET _ Definite=Ind|Gender=Fem|Number=Sing|PronType=Art 7 det _ _
6 vieille vieux ADJ _ Gender=Fem|Number=Sing 7 amod _ _
7 chèvre chèvre NOUN _ Gender=Fem|Number=Sing 0 root _ _
8 qui qui PRON _ PronType=Rel 9 nsubj _ _
9 avait avoir VERB _ Mood=Ind|Number=Sing|Person=3|Tense=Imp|VerbForm=Fin 7 acl:relcl _ _
10 sept sept NUM _ _ 11 nummod _ _
11 chevreaux chevreau NOUN _ Gender=Masc|Number=Plur 9 obj _ _
12 et et CCONJ _ _ 14 cc _ _
13 les le PRON _ Number=Plur|Person=3|PronType=Prs 14 obj _ _
14 aimait aimer VERB _ Mood=Ind|Number=Sing|Person=3|Tense=Imp|VerbForm=Fin 7 conj _ _
15 comme comme ADP _ _ 17 case _ _
16 chaque chaque DET _ Gender=Fem|Number=Sing 17 det _ _
17 mère mère NOUN _ Gender=Fem|Number=Sing 14 obl:mod _ _
18 aime aimer VERB _ Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin 14 xcomp _ _
19 ses son DET _ Gender=Masc|Number=Plur|Poss=Yes|PronType=Prs 20 det _ _
20 enfants enfant NOUN _ Gender=Masc|Number=Plur 18 obj _ SpaceAfter=No
21 . . PUNCT _ _ 7 punct _ _
Les colonnes 7 et 8 représentent les annotations en dépendances. Pour plus d'information sur le format CoNLL-U, vous pouvez consulter la documentation d'Universal Dependencies.
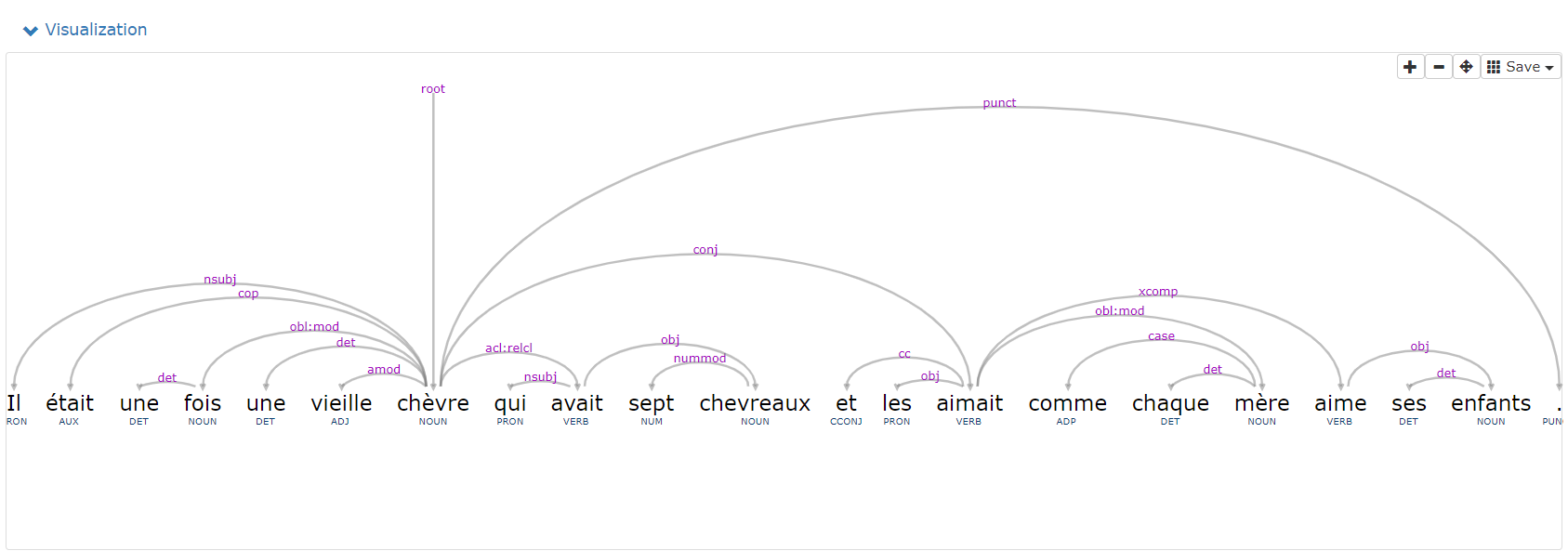
Visualisation des résultats (Visualization)
Les résultats sont donc représentés sous forme d'arbre des dépendances :
Téléchargement des résultats au format TCF
Dans le cas où le format CONLLU n'est pas voulue et que la conversion vers TCF a été réalisée Les relations de dépendances dans chaque phrase et entre les tokens sont ajoutées de la manière suivante dans le fichier TCF :
<tc:depparsing tagset="universal-dep" multigovs="false" emptytoks="true">
<tc:parse>
<tc:dependency func="nsubj" depIDs="t_0" govIDs="t_6"/>
<tc:dependency func="cop" depIDs="t_1" govIDs="t_6"/>
<tc:dependency func="det" depIDs="t_2" govIDs="t_3"/>
<tc:dependency func="obl:mod" depIDs="t_3" govIDs="t_6"/>
<tc:dependency func="det" depIDs="t_4" govIDs="t_6"/>
<tc:dependency func="amod" depIDs="t_5" govIDs="t_6"/>
<tc:dependency func="root" depIDs="t_6"/>
<tc:dependency func="nsubj" depIDs="t_7" govIDs="t_8"/>
<tc:dependency func="acl:relcl" depIDs="t_8" govIDs="t_6"/>
<tc:dependency func="nummod" depIDs="t_9" govIDs="t_10"/>
<tc:dependency func="obj" depIDs="t_10" govIDs="t_8"/>
<tc:dependency func="cc" depIDs="t_11" govIDs="t_13"/>
<tc:dependency func="obj" depIDs="t_12" govIDs="t_13"/>
<tc:dependency func="conj" depIDs="t_13" govIDs="t_6"/>
<tc:dependency func="case" depIDs="t_14" govIDs="t_16"/>
<tc:dependency func="det" depIDs="t_15" govIDs="t_16"/>
<tc:dependency func="obl:mod" depIDs="t_16" govIDs="t_13"/>
<tc:dependency func="xcomp" depIDs="t_17" govIDs="t_13"/>
<tc:dependency func="det" depIDs="t_18" govIDs="t_19"/>
<tc:dependency func="obj" depIDs="t_19" govIDs="t_17"/>
<tc:dependency func="punct" depIDs="t_20" govIDs="t_6"/>
</tc:parse>
[...]
</tc:depparsing>
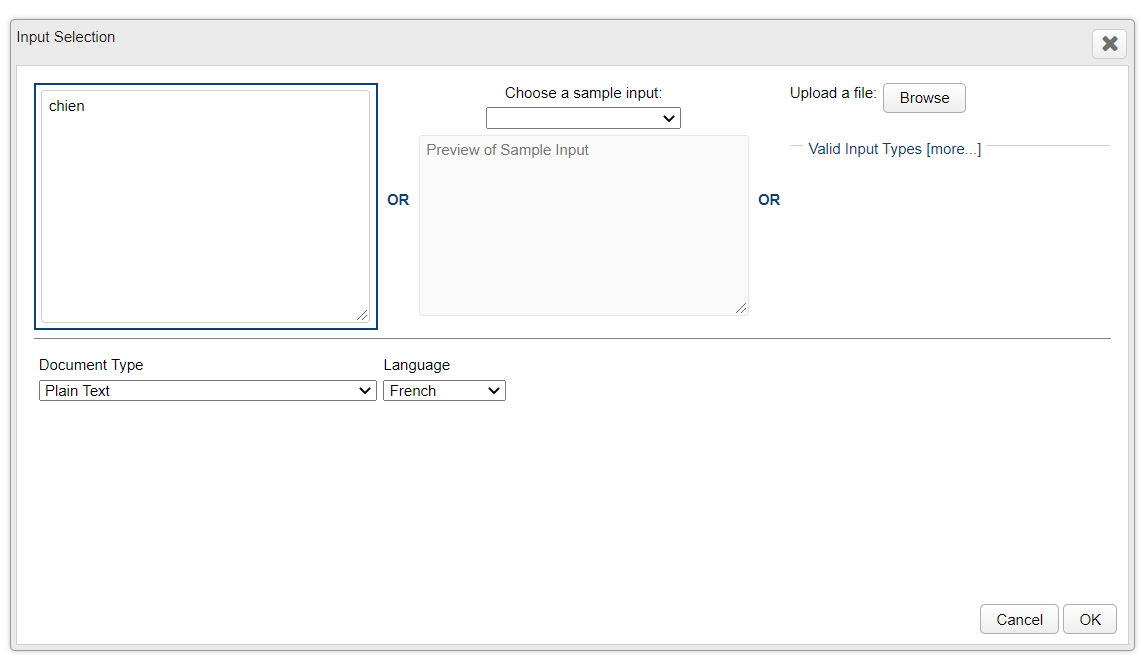
Comment voir des cooccurrences (voisins droits) fréquentes de "chien" ?
Création de la chaîne de traitement
J'entre en entrée le mot "chien" pour lequel je souhaite connaître les voisins droits fréquents.
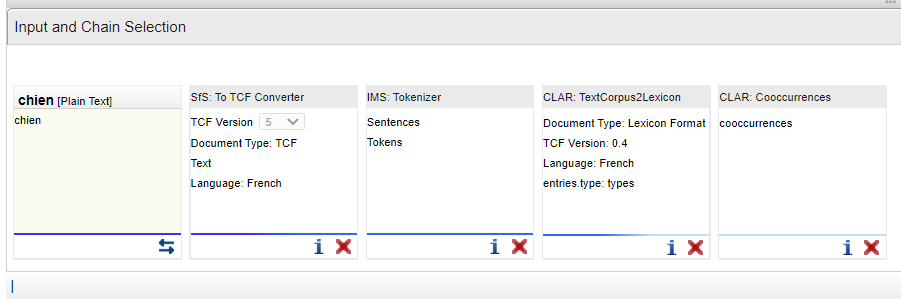
En prenant en compte quelles sont les entrées nécessaires et sorties ajoutées par chaque outil, pour atteindre l'outil souhaité "CLAR : Cooccurrences webservice (right neighbour) for fra_news_2011_3M", la chaîne de traitement pourrait être la suivante :
Je peux donc lancer l'annotation en cliquant sur le bouton .
Sortie
Une fois l'analyse effectuée, je peux donc :
Télécharger mes résultats en cliquant sur l'icône apparu en-dessous de CLAR : Cooccurrences de ma chaîne de traitement.
Visualiser mes résultats en cliquant sur l'icône apparu en-dessous de CLAR : Cooccurrences de ma chaîne de traitement.
Téléchargement des résultats
Dans le fichier basé sur XML, les résultats se présentent de la manière suivante :
<lx:cooccurrences>
<lx:cooccurrence func="right-neighbour">
<lx:sig measure="log-likelihood">143.49</lx:sig>
<lx:term entryID="e_0"></lx:term>
<lx:term>fou</lx:term>
</lx:cooccurrence>
<lx:cooccurrence func="right-neighbour">
<lx:sig measure="log-likelihood">123.98</lx:sig>
<lx:term entryID="e_0"></lx:term>
<lx:term>renifleur</lx:term>
</lx:cooccurrence>
<lx:cooccurrence func="right-neighbour">
<lx:sig measure="log-likelihood">111.55</lx:sig>
<lx:term entryID="e_0"></lx:term>
<lx:term>,</lx:term>
</lx:cooccurrence>
<lx:cooccurrence func="right-neighbour">
<lx:sig measure="log-likelihood">105.42</lx:sig>
<lx:term entryID="e_0"></lx:term>
<lx:term>aboie</lx:term>
</lx:cooccurrence>
<lx:cooccurrence func="right-neighbour">
<lx:sig measure="log-likelihood">95.14</lx:sig>
<lx:term entryID="e_0"></lx:term>
<lx:term>qui</lx:term>
</lx:cooccurrence>
<lx:cooccurrence func="right-neighbour">
<lx:sig measure="log-likelihood">76.88</lx:sig>
<lx:term entryID="e_0"></lx:term>
<lx:term>méchant</lx:term>
</lx:cooccurrence>
[...]
</lx:cooccurrences>